Safeguarding AI's Future Through Proactive Vulnerability Detection
We challenge the limits of AI to create systems that are smarter, stronger, and more reliable—relentlessly testing to ensure your systems stay resilient and reliable.
AI Agents Can Behave Badly

Inappropriate Language
Agents can generate offensive, harmful, or profane responses.

Security Risks
Agents can make your company susceptible to malicious prompts or exploits.

Misinformation
Often agents can provide incorrect, outdated, or misleading information.

Unintended Behaviors
Agents can cause pain points by responding in ways that confuse, frustrate, or mislead users.
Our Commitments
We are dedicated to ensuring AI agent security through rigorous testing and continuous monitoring
Thorough Testing
We rigorously test our agents to identify vulnerabilities across various scenarios
Strong Security
Our platform is built with security-first principles and regular security audits
Continuous Monitoring
Our systems continuously monitor agent behavior to detect anomalies in real-time
Transparent Reporting
We provide clear reporting on vulnerabilities found and how they were addressed
How It Works
Our platform provides a straightforward process to test and improve your AI agents
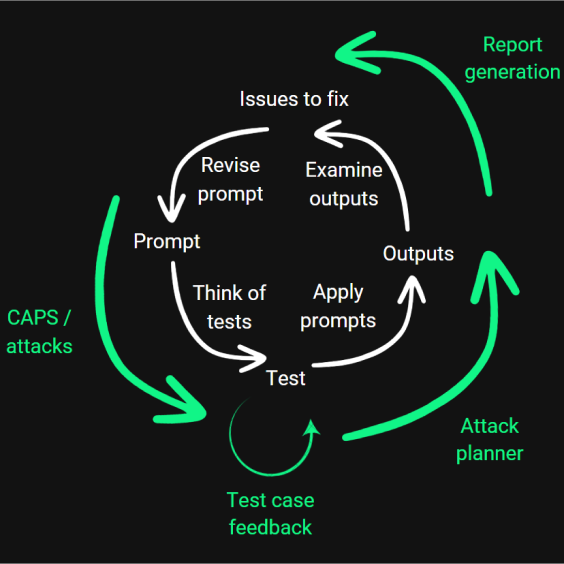
Connect Your Agent
Connect your AI agent to our platform
Automated Testing
Our platform runs your agent through thousands of test scenarios
Vulnerability Detection
Advanced algorithms identify and classify potential vulnerabilities
Comprehensive Report
Receive detailed reports with actionable insights to improve your agent
Continuous Improvement
Our platform learns from each test to improve detection capabilities, ensuring your AI agents remain secure as new threats emerge
Common Vulnerabilities
Understanding the most prevalent AI agent vulnerabilities is the first step toward securing your systems
Prompt Injection
Attackers can manipulate AI agents through carefully crafted inputs that override intended behaviors
Policy Violations
AI agents may inadvertently violate usage policies when facing edge cases or unusual inputs
Data Leakage
Agents can sometimes reveal sensitive information embedded in their training data
Jailbreaking
Sophisticated techniques that bypass AI safety guardrails entirely
Hallucinations
AI systems can generate false or misleading information that appears factual
Instruction Misalignment
Agents misinterpreting instructions in ways that produce unintended outputs
We detect and protect against these and many more vulnerabilities
Our Partnerships and Memberships
We collaborate with industry leaders to drive innovation in AI security and safety







Interested in partnering with us? Contact us to learn more.
Contact Us
Have questions or need assistance? Reach out to our team and we'll get back to you as soon as possible.